Tips for Navigating an Issue Tracker on GitHub

Image of a woman panning for gold generated by Stefanie Molin using NightCafe Studio.
Since publishing 5 Ways to Get Started in Open Source, I've gotten a lot of requests for tips on finding issues to work on. For the popular projects that people commonly set their sights on, there are often thousands of open issues to sift through, which can be overwhelming, regardless of your experience. In this article, I share my tips for navigating an issue tracker to narrow your search down to a manageable number of issues.
Filter with labels
Most project maintainers use labels to organize their issues and pull requests. As a prospective contributor, you can use these labels to narrow down your search through the issue tracker.
Each project is free to define its own labels, so the first step is to look through what's available. Let's take a look at the issue tracker in the pandas GitHub repository (click the Issues tab). As shown in the screenshot below, there are 3,588 open issues in the issue tracker tab and 146 labels:
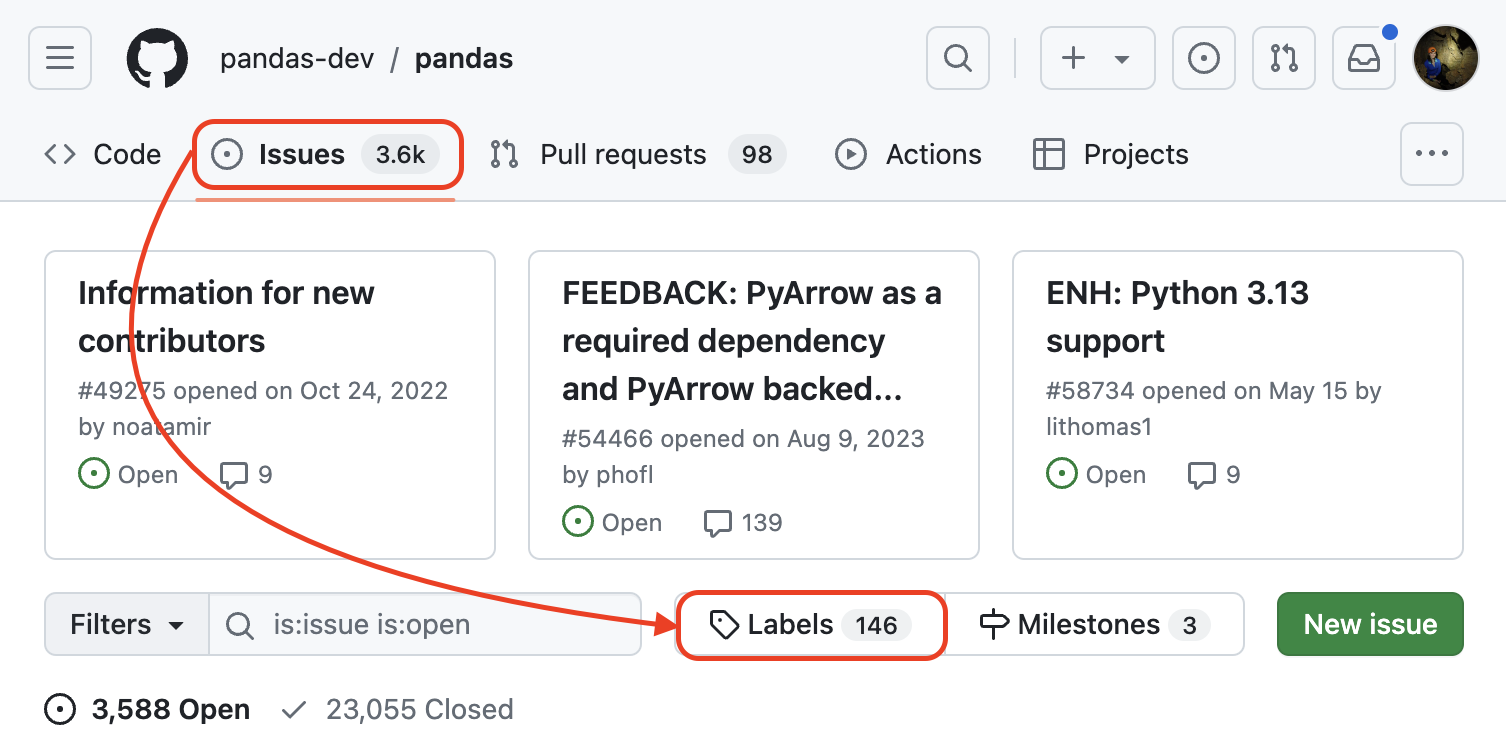
Screenshot of the issue tracker in the pandas GitHub repository on July 28, 2024 4:50 PM EDT. (source: Stefanie Molin)
Clicking on Labels brings up more information about the labels defined by the maintainers. We can see the label name, description (if provided), and the number of issues with that label:
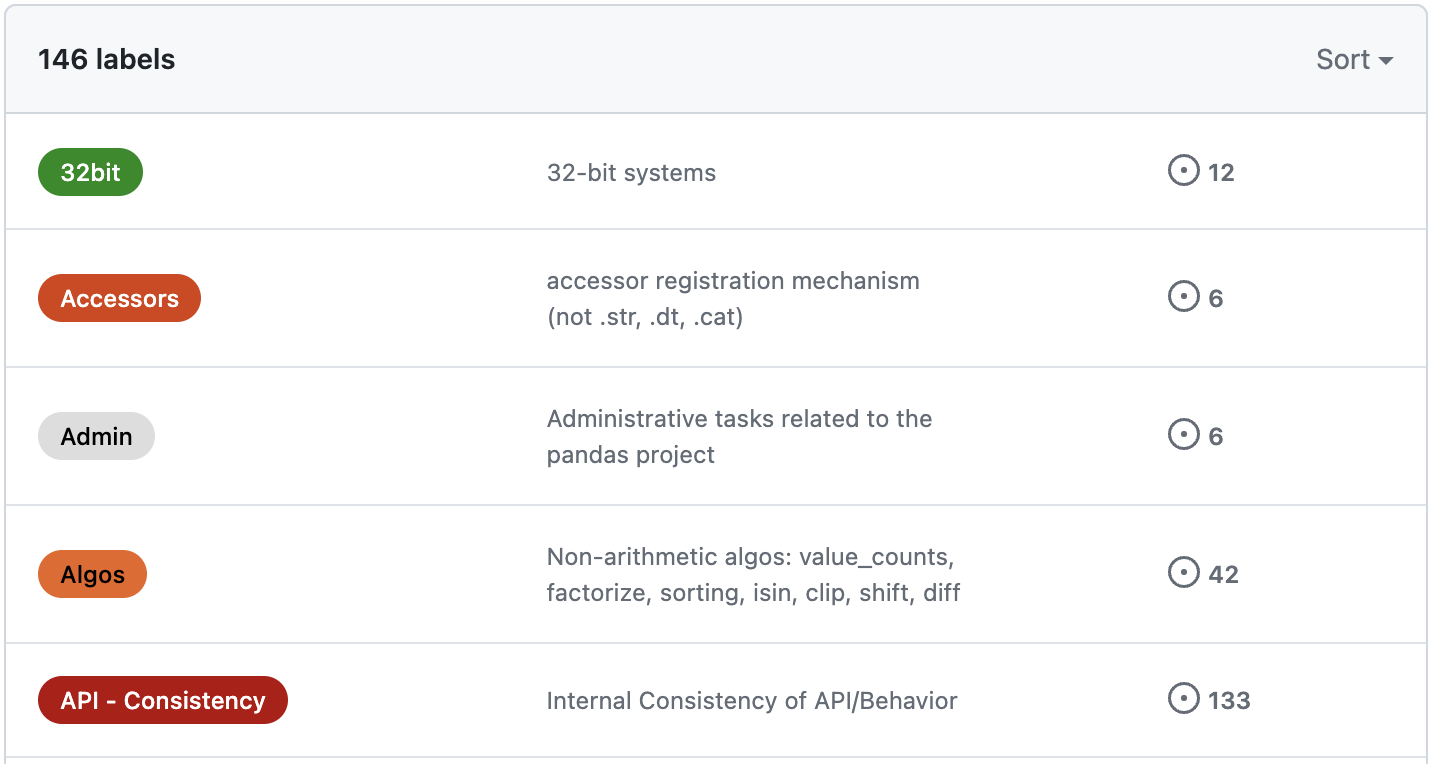
Screenshot of the labels used in the pandas GitHub repository on July 28, 2024 4:51 PM EDT. (source: Stefanie Molin)
While 146 is much less than 3,588, it is still a lot, but the good news is that these labels usually have patterns that can help you decide which ones to research further and which to rule out. For example, you may want to avoid anything that "needs" something, which is probably a task that the maintainers need to do to validate the issue before someone works on it (e.g., needs triage, needs discussion, etc.).
On the flip side, there are some standard labels that GitHub will generate when the repository is created that you should search for: good first issue, help wanted, documentation. Note that the project doesn't have to use or even keep these automatically-generated labels.
Another common pattern is for a repository to have labels for different parts of the codebase so that maintainers can specialize on certain topics and focus their triaging/reviewing efforts. Therefore, if there is a specific part of the library you are very familiar with, try searching for labels related to that.
Finally, some projects will use labels to indicate the level of perceived difficulty for a task. It's important to note that this is how difficult the maintainers perceive it, not how difficult you will actually find it. For example, I set up the Yellowbrick repository with pre-commit hooks, which was easy for me because I knew how to do it, but they had classified the issue as "level: expert" because no one on the team had done it before. The issue was four years old by the time I took it, but the maintainers were extremely grateful for my contribution. Search by difficulty if those labels exist, but don't limit yourself to easy or beginner issues.
Once you know what you want to search for, head back to the Issues tab and search for those labels. Note that you can search for multiple labels at once:
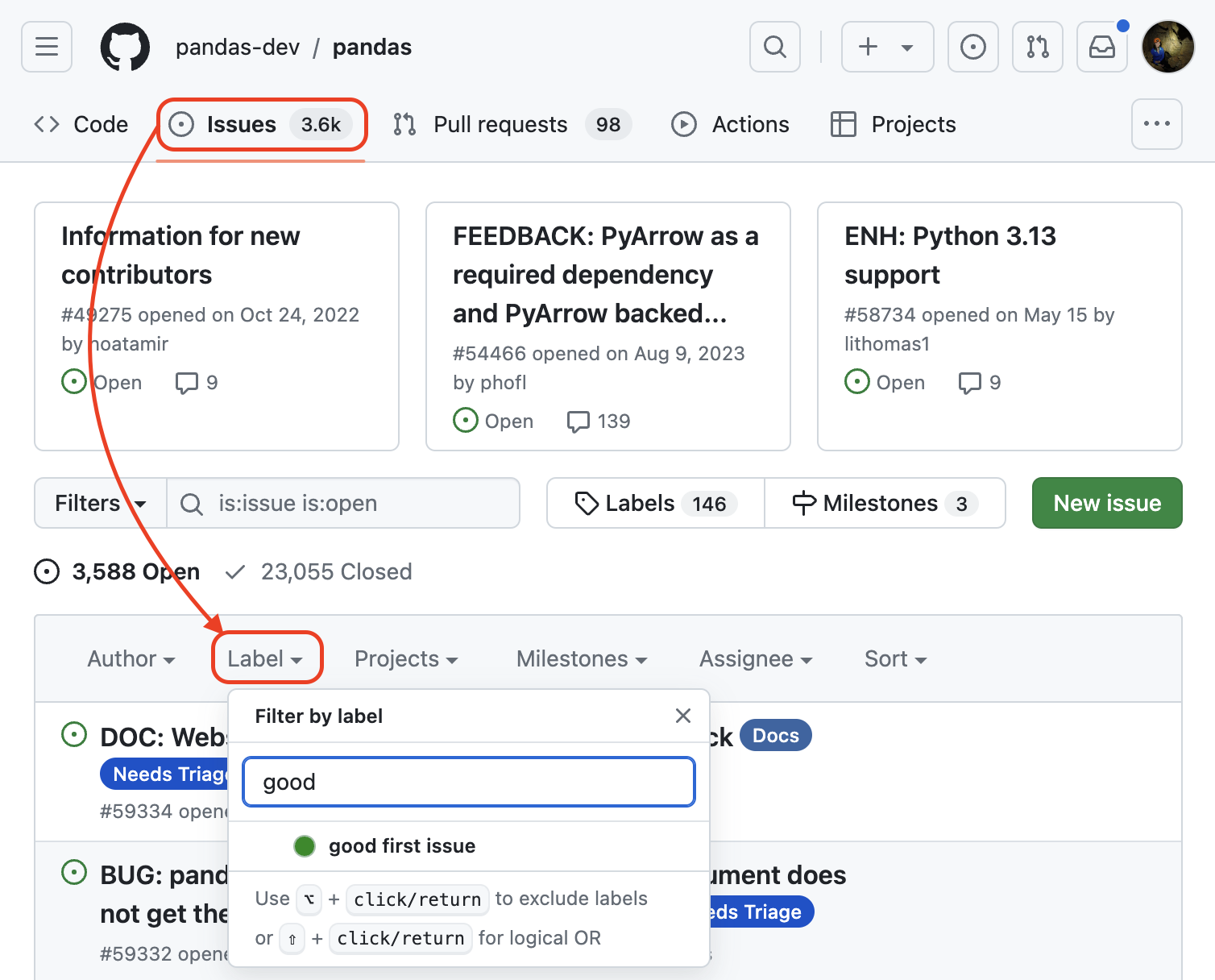
Screenshot of filtering issues in the pandas GitHub repository on July 28, 2024 5:00 PM EDT. (source: Stefanie Molin)
In this example, once we filter to issues labeled "good first issue," we go from 3,588 open issues to 62. The tricky thing with "good first issue" though, is that the competition is intense. As you can see here, the most recent issue is just three days old and already has a linked pull request:
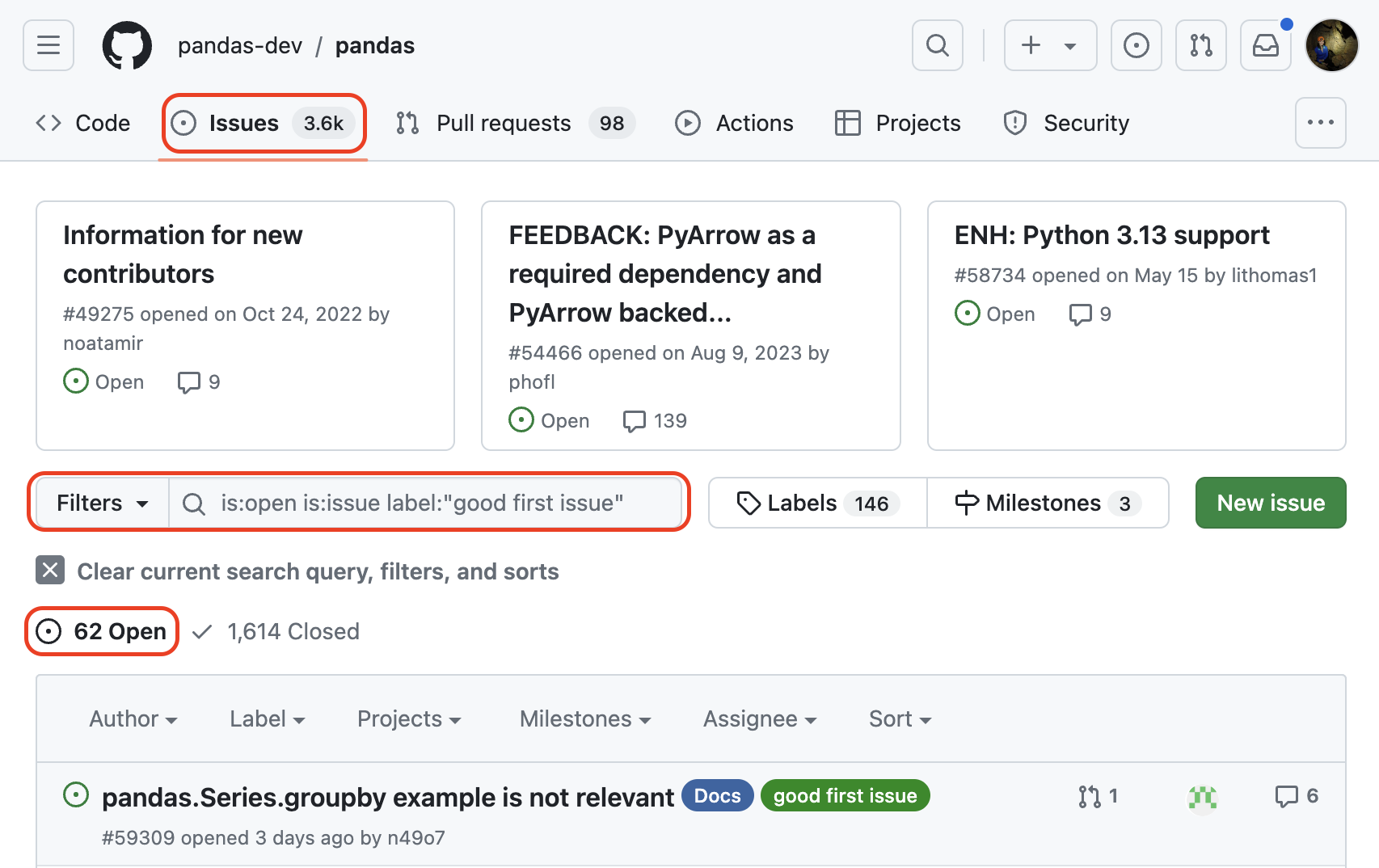
Screenshot of searching for issues labeled "good first issue" in the pandas GitHub repository on July 28, 2024 5:03 PM EDT. (source: Stefanie Molin)
Remember that just because something isn't labeled "good first issue," it doesn't mean that you can't do it as your first issue – don't underestimate yourself. After you come up with a list of labels to search for, you are more likely to find something that hasn't already been taken and that you feel comfortable tackling.
Avoid issues with lots of activity
Once you have filtered down the issues using labels, there may still be many left. Rather than clicking into each of them, I like to scroll through them scanning for those with little to no activity. All of the relevant information for this is on the right-hand side of the issue:

Screenshot of an issue in the Data Morph GitHub repository on July 28, 2024 5:40 PM EDT. (source: Stefanie Molin)
I avoid issues that have linked PRs or assignees as these likely mean that someone else is either working on this or nearly has their PR merged. I scan the issue tracker until I see an issue without them, at which point I use the number of comments to evaluate whether an issue is worth closer inspection.
I only click on issues that have little to no comments (the initial description to open up the issue doesn't count as a comment). In general, I find that many comments mean the task is not well-defined or that it will be hard to get buy-in from the maintainers, while issues with few comments are more straightforward both to a perspective contributor and the maintainer. However, there are two big caveats to this:
- An issue with no comments that wasn't put in by a maintainer is something you should avoid – always make sure the maintainers want to do something before working on it.
- Meta-issues, which I discuss next, outline a set of changes to apply across a codebase over many PRs. This means there will be lots of comments as people claim parts of it, and you may need to read the issue to see if there is still work remaining.
Look for meta-issues
Some projects make use of meta-issues, which, rather than mapping to a single change, will describe a change that needs to be applied across the codebase. This means that there will be many PRs that go toward the completion of the issue (and potentially, many contributors). If you can find one of these issues, I highly recommend you consider working on it, as not only will you have a description of what needs to be done, but you can use the PRs that came before you to help guide you.
The scikit-learn repository often has meta-issues, which typically include checklists of all the changes that need to be made. GitHub bubbles this up to show the completion progress. In the meta-issue below, there is one remaining change (53 of 54 tasks have been marked as completed). To the right of this, we see that there is already a linked PR (which will likely complete the 54th task), so it is unlikely to be an issue that we can work on. However, the issue was opened over a year ago (June 19, 2023), so it is possible that the person that put in that PR didn't finish, and you could take it over (comment and ask):

Screenshot of a scikit-learn meta-issue on GitHub on July 28, 2024 4:08 PM EDT. (source: Stefanie Molin)
Note that the use of tasks will depend on the repository – sometimes it is just a indication whether the person who put in the issue provided all requested information. You will have to read a few issues to figure this out.
Don't disregard older issues
People tend to navigate an issue tracker similarly to search engine results in that they don't go beyond the first few pages. This means that looking beyond that yields issues with less activity. Sometimes, these are still recently-opened issues, but they may be months or even years old. It's important to remember that just because an issue is still open does not mean it is still desired – if you see an older issue that interests you, comment on it to check if the maintainers still want to pursue it and state your interest in working on it if they are.
Note that meta-issues will often be open for longer as it takes more time for them to be completed, but sometimes things the maintainers really want, but can't prioritize end up buried in the issue tracker: the first contribution I made to seaborn was on the very last page and over nine months old, labeled as "wishlist." Consider the age of the issue in conjunction with the size and maturity of the project: an older issue in a small or slowly-developing repository will likely be less stale than one in a large or rapidly-evolving repository.
Searching through an open source project's issue tracker is a great way to find something to work on, but it will likely be the hardest part of making a contribution due to the sheer volume of issues to sift through. Use the strategies presented in this article to narrow your search down to a manageable amount of issues to research further. Let me know how it goes for you in the comments below and/or on social media, by tagging me on LinkedIn or Twitter.
Never miss a post: sign up for my newsletter.

